照这样下去,AI 早晚能出片。
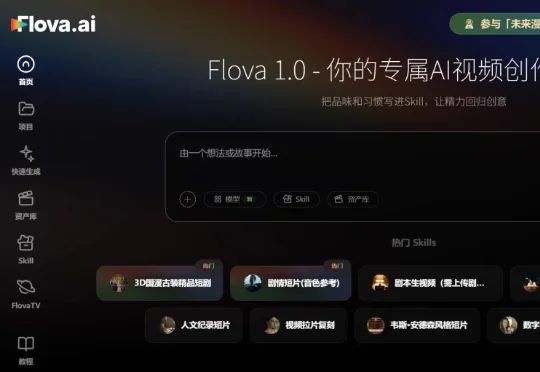
照这样下去,AI 早晚能出片。我最近又玩了一个新的视频制作平台,名叫 Flova,它的思路就是我上边说的这个方向。它不仅仅是一个调用单个模型的生成工具,而是一个面向 AI 视频 / AI 影视创作的全能六边形 Agent。
来自主题: AI资讯
8848 点击 2026-07-10 09:51
 搜索
搜索
我最近又玩了一个新的视频制作平台,名叫 Flova,它的思路就是我上边说的这个方向。它不仅仅是一个调用单个模型的生成工具,而是一个面向 AI 视频 / AI 影视创作的全能六边形 Agent。

PJ Ace 在推文中兴奋地表示,他们借助 Utopai Studios 推出的下一代 AI 视频模型和智能体 PAI2.0, 以好莱坞灾难片大师罗兰·艾默里奇(Roland Emmerich)的视听风格,硬核「复活」了一段 250 年前激情澎湃、颠覆想象的美国独立日「真实历史影像」。

AI 视频初创公司 Higgsfield AI 正在与投资者洽谈,筹资 3 亿美元至 5 亿美元,投资前估值为 50 亿美元,据两位知情于此次筹资活动的人士透露。Higgsfield 制作了一个用于 AI 图像和视频生成的平台,允许用户从文本创建视觉内容,并编辑视频的运动控制、音频和其他组件。

周六在家刷抖音,看到一个脱口秀片段,特有意思。点进去账号,连续看了三条之后,我才反应过来,这居然是 AI 做的。
王珏 (左)方晨(右) 推荐语 动画是一个被低估的品类。它比真人影视更早拥抱数字化工具,比短视频承载更复杂的叙事,从迪士尼到吉卜力,证明了自己能撑起全年龄段的内容消费和完整的商业闭环。但动画的产能瓶颈
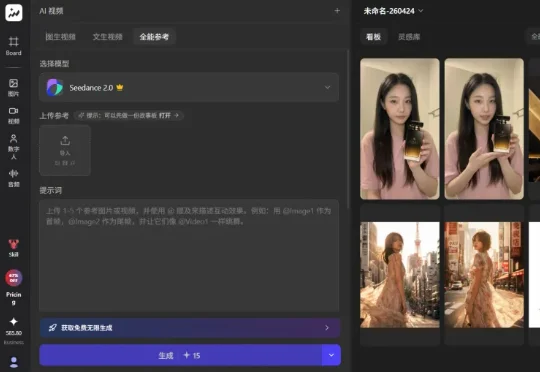
做过 AI 视频的都懂,除了 Seedance 2.0 本身的高定价,废片所烧掉的 token 算力也是一笔不小的开支。但在 Topview 平台,直接把这笔最大试错成本给重新定义了!热门视频生成模型 Seedance 2.0,加上最新的图片生成模型 Image 2,订阅 Ultra Plan,可不限量使用。
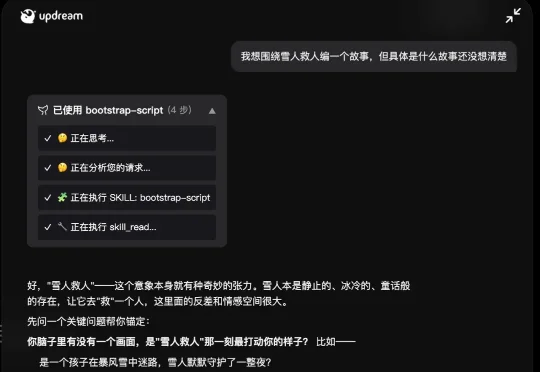
这段时间,updream 的内测消息在创作者圈子里悄悄传开了。它是一款面向专业创作者的 AI 视频创作产品,在前几天的 B 站首届 AI 创作大赛颁奖活动现场首次公开亮相。消息扩散之后,各创作者社群里很快出现了「求码」的声音。一款产品还没正式上线,就让这批见过不少 AI 神器的人主动排队,这本身就值得聊聊。

Mirage(原 Captions)宣布获得 7500 万美元 融资,由 General Catalyst 旗下 Customer Value Fund(CVF)提供。这类资金的逻辑,与传统 VC 明显不同,它更关注已经被验证的增长模型与单位经济,而不是单纯押注未来。

在会上,昆仑万维旗下天工 AI 重磅发布了全新 AI 游戏世界模型 Matrix-Game 3.0、AI 视频大模型 SkyReels V4 和 AI 音乐大模型 Mureka V9,在继续强化 AIGC 理解与生成能力的同时,进一步推进 AI 对物理世界的建模与仿真。
就在昨天,全球 AI 视频生成领域迎来了一场 “超级地震”——OpenAI 竟然意外叫停了万众瞩目的 Sora 2 项目。